We got some sample data for Elasticsearch. 1.5 million records to be precise. We will use Filebeats and Elasticsearch pipelines to load up the data into the cluster. The data has text, numbers and even geo points ! The data size on disk will be around 640MB (Windows environment). So let get on with it.
WHY
This is simple to answer. Good sample data for Elasticsearch is important for practicing the concepts you learn. More so for the Kibana analytics. My previous post on sample Elasticsearch data was a rather innocent attempt at solving this. Fast forward 2019, I have come across much better datasets. The issue always has been the ingest of data. Data found on web almost always has some format issue. Or some missing fields. Or some outliers. In this post I do all the heavy lifting so that life is simpler for you.
SETUP
Elasticsearch version: 7.2.0
Filebeat version: 7.2.0
Environment: Windows 10
Data size on disk after ingest: 640MB
HOW
So our sample data for Elasticsearch is actually coming from a dataset provided by NYC OpenData. Feel free to have a quick look at the structure of the data. You have to download the data and then save it at some place.
I saved it at: C:\Data\NYPD_Motor_Vehicle_Collisions_Crashes.csv
The data has some issues with the Longitude and the Latitudes. I am not an expert but it might be that they are cartesian coordinates. Elasticsearch expects the geo_point to have Latitude to be in range of [-90,90]. Longitude range accepted by Elasticsearch is [-180,180]. There are some columns where the value of Longitude is -201 something. So I will reject all those rows using painless script in Elasticsearch pipeline. Also the rows where the latitude and longitude are missing will be dropped.
Refer to my previous posts on filebeats and Elasticsearch pipeline for more information on how these components work. If you want to go official then you can refer to the latest filebeat documentation. For elasticsearch pipelines refer to this link.
To process this sample data , we will use Elasticsearch pipelines. I have named the pipeline as crash_pipeline. Go to the development tab on kibana and execute this script.
PUT _ingest/pipeline/crash_pipeline
{
"description": "nypd crash data pipleline",
"processors": [
{
"set": {
"field": "message",
"value": "{{message}},drop"
}
},
{
"split": {
"field": "message",
"target_field": "splitdata",
"separator": ","
}
},
{
"foreach": {
"field": "splitdata",
"processor": {
"trim": {
"field": "_ingest._value"
}
}
}
},
{
"script": {
"lang": "painless",
"source": "ctx.Timestamp = ctx.splitdata[0] + ' ' + ctx.splitdata[1];ctx.Borough = ctx.splitdata[2];ctx.Zipcode = ctx.splitdata[3];ctx.Latitude = ctx.splitdata[4];ctx.Longitude = ctx.splitdata[5];ctx.Loc = ctx.splitdata[6];ctx.On_street_name = ctx.splitdata[7];ctx.Cross_street_name = ctx.splitdata[8];ctx.Off_street_name = ctx.splitdata[9];ctx.Number_of_persons_injured = ctx.splitdata[10];ctx.Number_of_persons_killed = ctx.splitdata[11];ctx.Number_of_pedestrians_injured = ctx.splitdata[12];ctx.Number_of_pedestrians_killed = ctx.splitdata[13];ctx.Number_of_cyclists_injured = ctx.splitdata[14];ctx.Number_of_cyclists_killed = ctx.splitdata[15];ctx.Number_of_motorists_injured = ctx.splitdata[16];ctx.Number_of_motorists_killed = ctx.splitdata[17];ctx.Contributing_factor_vehicle_1 = ctx.splitdata[18];ctx.Contributing_factor_vehicle_2 = ctx.splitdata[19];ctx.Contributing_factor_vehicle_3 = ctx.splitdata[20];ctx.Contributing_factor_vehicle_4 = ctx.splitdata[21];ctx.Contributing_factor_vehicle_5 = ctx.splitdata[22];ctx.Collsion_Id = ctx.splitdata[23];ctx.Vehicle_type_code_1 = ctx.splitdata[24];ctx.Vehicle_type_code_2 = ctx.splitdata[25];ctx.Vehicle_type_code_3 = ctx.splitdata[26];ctx.Vehicle_type_code_4 = ctx.splitdata[27];ctx.Vehicle_type_code_5 = ctx.splitdata[28]"
}
},
{
"date": {
"field": "Timestamp",
"formats": [
"MM/dd/yyyy H:mm"
]
}
},
{
"convert": {
"field": "Latitude",
"type": "float",
"ignore_failure": true
}
},
{
"convert": {
"field": "Longitude",
"type": "float",
"ignore_failure": true
}
},
{
"set": {
"if": "ctx.Latitude != '' && ctx.Latitude <= 90 && ctx.Latitude >= -90 && ctx.Longitude != '' && ctx.Longitude >= -180 &&ctx.Longitude <= 180",
"field": "Location",
"value": "{{Latitude}},{{Longitude}}"
}
},
{
"remove": {
"field": [
"Loc",
"Timestamp",
"Longitude",
"Latitude",
"splitdata"
]
}
}
],
"on_failure": [
{
"set": {
"field": "_index",
"value": "failed-{{ _index }}"
}
}
]
}
Forgive the messy painless script to process the csv lines. Its high time they released a csv processor for Elasticsearch pipeline.
Here is the filebeat yml file which we will use. I have creatively named it as filebeat_nypd.yml.
setup.template.append_fields:
- name: Location
type: geo_point
- name: Zipcode
type: integer
- name: Number_of_persons_injured
type: integer
- name: Number_of_persons_killed
type: integer
- name: Number_of_pedestrians_injured
type: integer
- name: Number_of_pedestrians_killed
type: integer
- name: Number_of_cyclists_injured
type: integer
- name: Number_of_cyclists_killed
type: integer
- name: Number_of_motorists_injured
type: integer
- name: Number_of_motorists_killed
type: integer
- name: Collsion_Id
type: integer
filebeat.inputs:
- paths:
- C:\Data\NYPD_Motor_Vehicle_Collisions_Crashes.csv
input_type: log
exclude_lines: ['^DATE']
output.elasticsearch:
hosts: ["http://localhost:9200"]
pipeline: crash_pipeline
logging.level: info
logging.to_files: true
logging.files:
path: C:\filebeatStuff\logs
name: filebeat
keepfiles: 7
permissions: 0644
You will need to install Filebeat. Make sure that the version matches the Elasticsearch version. In this case it will be 7.2.0.
Here is how to run Filebeat manually (on Windows):
1. Go to Program Files/Filebeat.
2. Put the filebeat_nypd.yml there. You will need admin privileges.
3. Open a command terminal with admin privileges.
4. Go to Program Files/Filebeat.
5. Run filebeat.exe -c filebeat_nypd.yml
Keep checking the elasticsearch and filebeat logs. They should not have any errors.

Once it is done you will have around 1.5 million records waiting for you in Kibana. The date range is somewhere from 2012 till 2019 at time of writing this post.
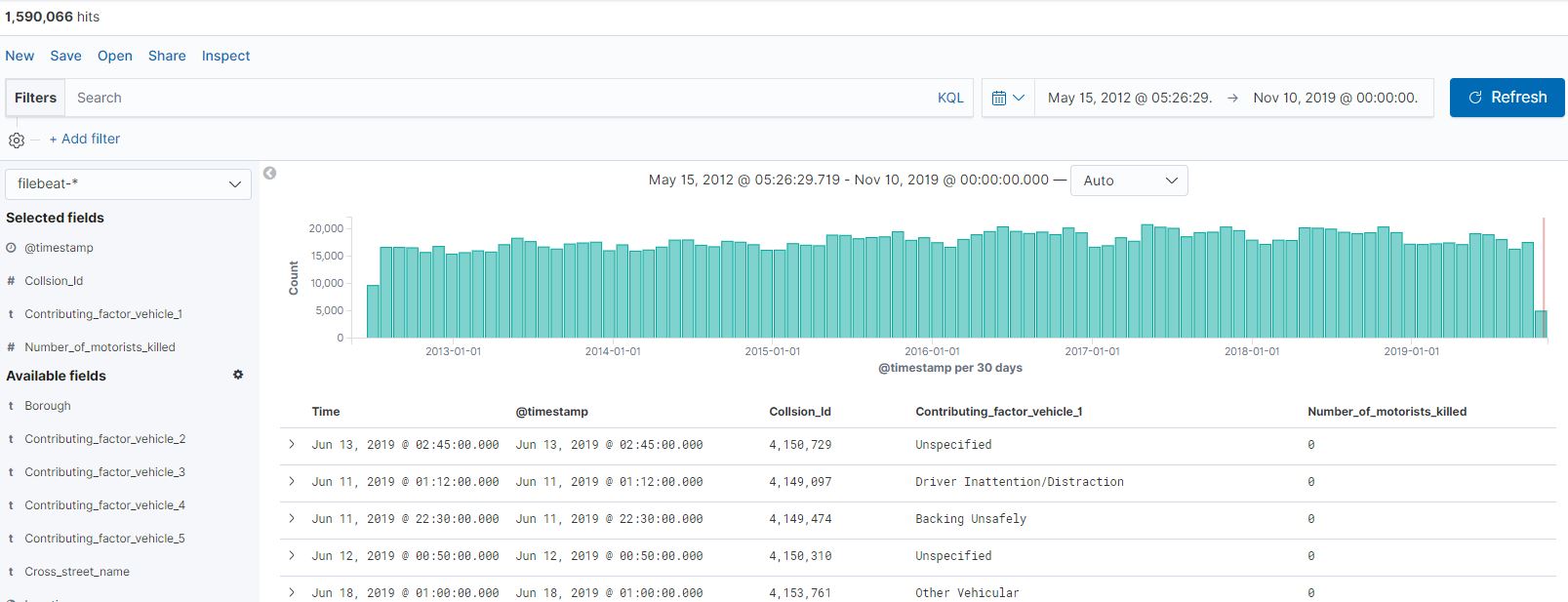
Note: Time is the time of ingest. You should be using for @timestamp as the date of incident report.
And this is how you load sample data for Elasticsearch.